一、简介
我们知道 flink 对于外部数据源的操作可以通过自带的连接器,或者自定义 sink 和 source 实现数据的交互。
那么为啥还需要异步 IO 呢?那时因为对于实时处理,当我们需要使用外部存储数据参与计算时,与外部系统之间的交互延迟对流处理的整个工作进度起决定性的影响。
如果我们是使用传统方式 map function 等算子里访问外部存储,实际上该交互过程是同步的。
比如请求 a 发送到数据库,那么 map function 会一直等待响应。在很多案例中,这个等待过程是非常浪费函数时间的。
二、异步IO原理
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,于1.2版本引入。
主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
流计算系统中经常需要与外部系统进行交互。比如需要查询外部数据库以关联上用户的额外信息。
通常我们的实现方式是向数据库发送用户 a 的查询请求,然后等待结果返回。
在这之前我们无法发送用户的查询请求。
这是一种同步访问的模式。
如下图左边所示。

图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。
也就是说,你可以连续地向数据库发送用户a、b、c等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。这也正是 Async I/O 的实现原理。
三、Async I/O的前提
使用 Async I/O 的前提是需要一个支持异步请求的客户端。当然,没有异步请求客户端的话,也可以将同步客户端丢到线程池中执行作为异步客户端。
Flink 提供了非常简洁的 API,让用户只需要关注业务逻辑,一些脏活累活,比如消息顺序性和一致性保证都由框架处理。
四、如何使用Async I/O
我们需要自定义一个类实现 RichAsyncFunction 这个抽象类,实现其中的抽象方法。这点和自定义 source 很像。
主要抽象方法如下,然后在 asyncInvoke() 使用 CompletableFuture 执行异步操作。
open()
asyncInvoke()
timeout()
close()
然后在 AsyncDataStream 中使用我们定义好的类,去实现主流异步的访问外部数据源。
五、AsyncDataStream
AsyncDataStream 有两个静态方法 orderedWait 和 unorderedWait 对应了两种输出模式:有序和无序。
- 有序:消息的发送顺序与接受到的顺序相同(包括 watermark ),也就是先进先出。
- 无序:在 ProcessingTime 的情况下,完全无序,先返回的结果先发送。在 EventTime 的情况下,watermark 不能超越消息,消息也不能超越 watermark,也就是说 watermark 定义的顺序的边界。在两个 watermark 之间的消息的发送是无序的,但是在watermark之后的消息不能先于该 watermark 之前的消息发送。
六、原理实现
AsyncDataStream.(un)orderedWait 的主要工作就是创建了一个 AsyncWaitOperator。
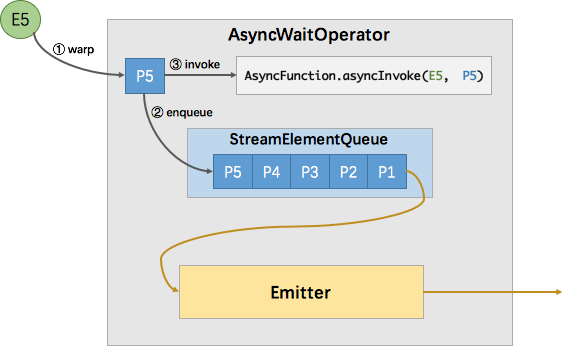
AsyncWaitOperator是支持异步 IO 访问的算子实现,该算子会运行 AsyncFunction 并处理异步返回的结果,其内部原理如下图所示。

如图所示,AsyncWaitOperator 主要由两部分组成 StreamElementQueue 和 Emitter。
StreamElementQueue 是一个 Promise 队列,所谓 Promise 是一种异步抽象表示将来会有一个值,这个队列是未完成的 Promise 队列,也就是进行中的请求队列。Emitter 是一个单独的线程,负责发送消息(收到的异步回复)给下游。
图中 E5 表示进入该算子的第五个元素”Element-5”。在执行过程中,首先会将其包装成一个 “Promise” P5,然后将P5放入队列。
最后调用 AsyncFunction 的 ayncInvoke 方法该方法会向外部服务发起一个异步的请求并注册回调。
该回调会在异步请求成功返回时调用 AsyncCollector.collect 方法将返回的结果交给框架处理。
实际上 AsyncCollector是一个 Promise 也就是 P5在调用 collect 的时候,会标记 Promise 为完成状态,并通知 Emitter 线程有完成的消息可以发送了。
Emitter 就会从队列中拉取完成的 Promise 并从 Promise 中取出消息发送给下游。
(1)消息的顺序性
上文提到 Async I/O 提供了两种输出模式。
其实细分有三种模式:有序,ProcessingTime 无序,EventTime 无序。
Flink 使用队列来实现不同的输出模式,并抽象出一个队列的接口 StreamElementQueue 。
这种分层设计使得 AsyncWaitOperator 和 Emitter 不用关心消息的顺序问题。
StreamElementQueu有两种具体实现,分别是 OrderedStreamElementQueue 和 UnorderedStreamElementQueue。UnorderedStreamElementQueue 比较有意思,它使用了一套逻辑巧妙地实现完全无序和 EventTime 无序。
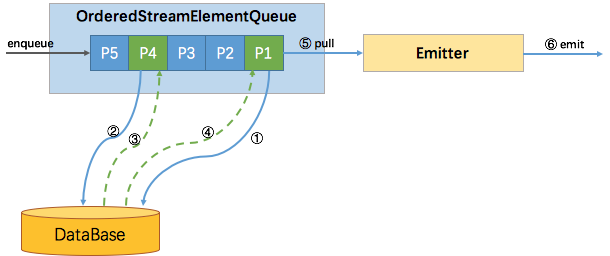
(2)有序
有序比较简单,使用一个队列就能实现。所有新进入该算子的元素(包括 watermark),都会包装成 Promise 。
并按到达顺序放入该队列。
如下图所示,尽管 P4 的结果先返回,但并不会发送。只有 P1(队首)的结果返回了才会触发 Emitter 拉取队首元素进行发送。
(3)ProcessingTime 无序
ProcessingTime 无序也比较简单,因为没有 watermark,不需要协调 watermark 与消息的顺序性。
所以使用两个队列就能实现,一个 uncompletedQueue ,一个 completedQueue。
所有新进入该算子的元素,同样的包装成 Promise 并放入 uncompletedQueue 队列,当uncompletedQueue队列中任意的Promise返回了数据,则将该 Promise 移到 completedQueue队列中,并通知 Emitter 消费。如下图所示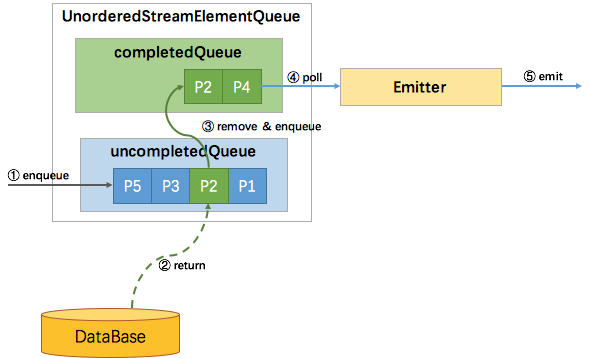
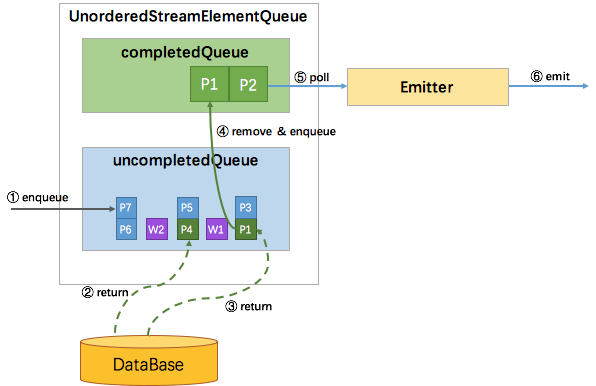
(4)EventTime 无序
EventTime 无序类似于有序与 ProcessingTime 无序的结合体。
因为有 watermark,需要协调 watermark 与消息之间的顺序性,所以 uncompletedQueue 中存放的元素从原先的 Promise 变成了 Promise 集合。
如果进入算子的是消息元素,则会包装成 Promise 放入队尾的集合中;如果进入算子的是 watermark,也会包装成 Promise 并放到一个独立的集合中,再将该集合加入到 uncompletedQueue 队尾,最后再创建一个空集合加到uncompletedQueue 队尾。
这样,watermark 就成了消息顺序的边界。只有处在队首的集合中的 Promise 返回了数据,才能将该 Promise 移到 completedQueue 队列中,由 Emitter 消费发往下游。
只有队首集合空了,才能处理第二个集合。这样就保证了当且仅当某个 watermark 之前所有的消息都已经被发送了,该 watermark 才能被发送。过程如下图所示
七、自定义异步查询
在异步IO查询外部存储时,对于提供异步查询的客户端来说可以直接使用,但是对于没有提供异步查询的客户端应该怎么做呢?
我们可以将查询请求丢到一个线程池中,将这个线程池看做是一个异步的客户端,来帮助我们完成查询请求。
通过线程池方式来帮助我们完成异步请求,关键在于线程池的 core 大小如何设置,如果设置过大,会到导致创建很多个线程,势必会造成CPU的压力比较大。
由于大多数情况下集群是没有做 CPU 隔离策略的就会影响到其他任务。
如果设置过小,在处理的速度上根不上就会导致任务阻塞。
可以做一个粗略的估算:假如任务中单个 Task 需要做维表关联查询的数据每秒会产生 1000 条,也就是 1000 的 TPS,我们希望能够在 1 s 以内处理完这 1000 条数据。
如果外部单次查询耗时是 10ms,那我们就需要 10 个并发同时执行,也就是我们需要的coreSize 是10。
以查询mysql为例
class ExecSideFunction extends RichAsyncFunction[String, String] {
var executors: Executor = _
var sqlTemplate: String = _
override def open(parameters: Configuration): Unit = {
executors = new ThreadPoolExecutor(10, 10, 0, TimeUnit.SECONDS, new ArrayBlockingQueue[Runnable](1000))
sqlTemplate = "select value from tbl1 where id=?"
}
override def asyncInvoke(input: String, resultFuture: ResultFuture[String]): Unit = {
executors.execute(new Runnable {
override def run(): Unit = {
val con = ConnectionFactory.getConnection("sourceId").asInstanceOf[Connection]
val sql = sqlTemplate.replace("?", parseKey(input))
MysqlUtil.executeSelect(con, sql, rs =>
val res = new util.ArrayList[String]()
while (rs.next()) {
val v = rs.getString("value")
res.add(fillData(input, v))
}
resultFuture.complete(res)
})
con.close()
}
})
}
}
八、案例:异步IO实现读入redis中的维表数据
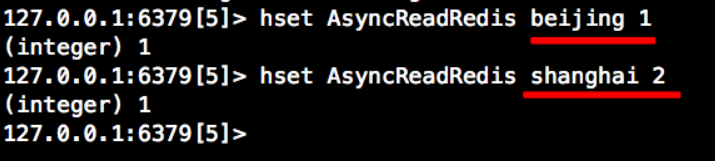
数据准备
redis中插入两条维度数据
ab.txt文件中插入数据
1,beijing
2,shanghai
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
3,beijing
代码
public class AsyncReadRedis extends RichAsyncFunction<String,String> {
//获取连接池的配置对象
private JedisPoolConfig config = null;
//获取连接池
JedisPool jedisPool = null;
//获取核心对象
Jedis jedis = null;
//Redis服务器IP
private static String ADDR = "127.0.0.1";
//Redis的端口号
private static int PORT = 6379;
//访问密码
private static String AUTH = "XXXXXX";
//等待可用连接的最大时间,单位毫秒,默认值为-1,表示永不超时。如果超过等待时间,则直接抛出JedisConnectionException;
private static int TIMEOUT = 10000;
private static final Logger logger = LoggerFactory.getLogger(AsyncReadRedis.class);
//初始化连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
config = new JedisPoolConfig();
jedisPool = new JedisPool(config, ADDR, PORT, TIMEOUT, AUTH, 5);
jedis = jedisPool.getResource();
}
//数据异步调用
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception {
// 发起一个异步请求,返回结果的 future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
String[] split = input.split(",");
String name = split[1];
String s = jedis.hget("AsyncReadRedis", name);
return s;
}
}).thenAccept((String dbResult) -> {
// 设置请求完成时的回调: 将结果传递给 collector
resultFuture.complete(Collections.singleton(dbResult));
});
}
@Override
public void timeout(String input, ResultFuture resultFuture) throws Exception {
}
@Override
public void close() throws Exception {
super.close();
}
}
测试使用:
因为 jedis 不支持异步操作,所以 AsyncDataStream.unorderedWait 的并行度参数要设置成1。
线上使用建议使用支持异步操作的Redisson
public class AsynsRedisRead {
public static void main(String[] args) throws Exception {
System.out.println("===============》 flink任务开始 ==============》");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置检查点时间间隔
env.enableCheckpointing(5000);
//设置检查点模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
System.out.println("===============》 开始读取kafka中的数据 ==============》");
SingleOutputStreamOperator<String> kafkaData = env.readTextFile("/Users/apple/app/ab.txt");
SingleOutputStreamOperator<String> unorderedWait = AsyncDataStream.unorderedWait(kafkaData, new AsyncReadRedis(), 1000, TimeUnit.MICROSECONDS, 1);
unorderedWait.print();
//设置程序名称
env.execute("data_to_redis_wangzh");
}
}
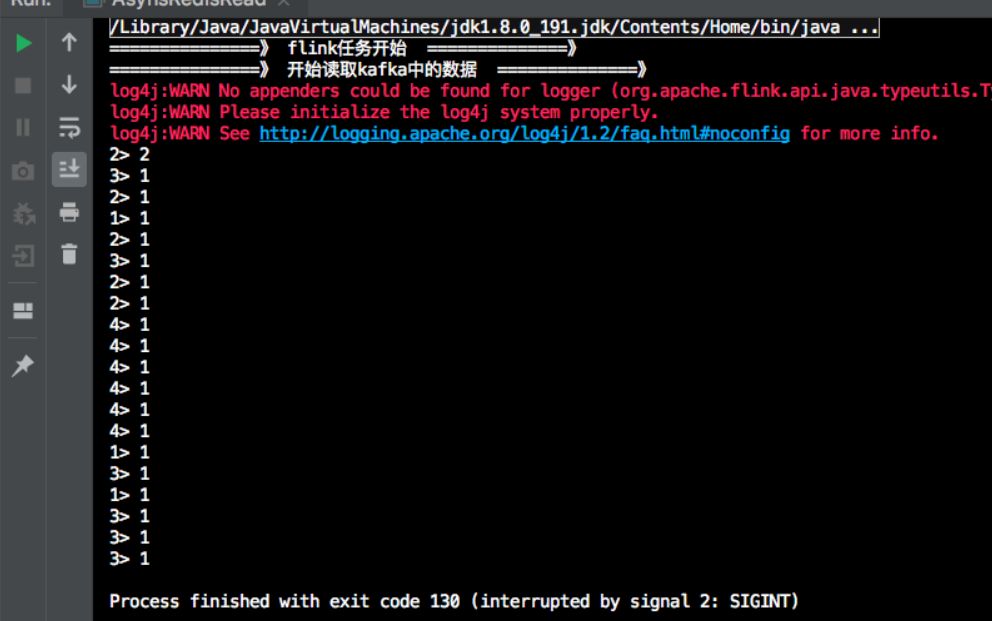
结果:
原创文章,作者:kk,如若转载,请注明出处:http://www.wangkai123.com/68/