一、Flink metrics简介
Flink 的 metrics 是 Flink 公开的一个度量系统,metrics 也可以暴露给外部系统,通过在 Flink 配置文件 conf/flink-conf.yaml 配置即可,Flink原生已经支持了很多reporter,如 JMX、InfluxDB、Prometheus 等等。
我们也可以自定义指标通过 metric 收集,实际开发时经常需要查看当前程序的运行状况,flink 提供了 UI 界面,有比较详细的统计信息。
但是 UI 界面也有不完善的地方,比如想要获取 flink 的实时吞吐。本文将详细介绍如何通过 metric 监控 flink 程序,自定义监控指标以及 metrics 在 flink 的 UI 界面的应用。
二、Metrics在UI页面上的应用
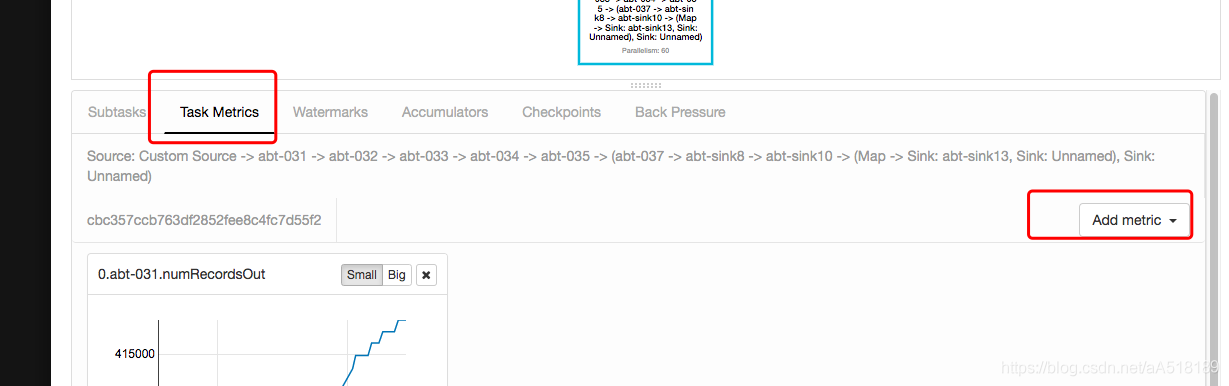
在 flink 的 UI 的界面上我们点击任务详情,然后点击 Task Metrics 会弹出如下的界面,在 add metic 按钮上 我们可以添加我需要的监控指标。
注意:如果点击 Task Metrics 没有显示 Add metics 点击一下任务的 DAG 图就会显示出来,当我们点击了 DAG 图中某个算子的名字,那么 Add metric 显示的就是该算子的监控指标,且按照分区显示,算子名前置的数字就是分区号。

三、各个指标的含义
关于各个指标的含义官网上有详细介绍:
四、自定义监控指标
案例:在map算子内计算输入的总数据,设置 :
MetricGroup为:flink_test_metric,指标变量为:mapDataNub
DataStream<String> userData = kafkaData.map(new RichMapFunction<String, String>() {
Counter mapDataNub;
@Override
public void open(Configuration parameters) throws Exception {
mapDataNub= getRuntimeContext()
.getMetricGroup()
.addGroup("flink_test_metric")
.counter("mapDataNub");
}
@Override
public String map(String s) {
String s1 ="";
try {
String[] split = s.split(",");
long userID = Long.parseLong(split[0]);
long itemId = Long.parseLong(split[1]);
long categoryId = Long.parseLong(split[2]);
String behavior = split[3];
long timestamp = Long.parseLong(split[4]);
Map map = new HashMap();
map.put("userID", userID);
map.put("itemId", itemId);
map.put("categoryId", categoryId);
map.put("behavior", behavior);
map.put("timestamp", timestamp);
s1 = JSON.toJSONString(map);
mapDataNub.inc();
System.out.println("数据"+map.toString());
} catch (NumberFormatException e) {
e.printStackTrace();
}
return s1;
}
程序启动之后就可以在任务的ui界面上查看
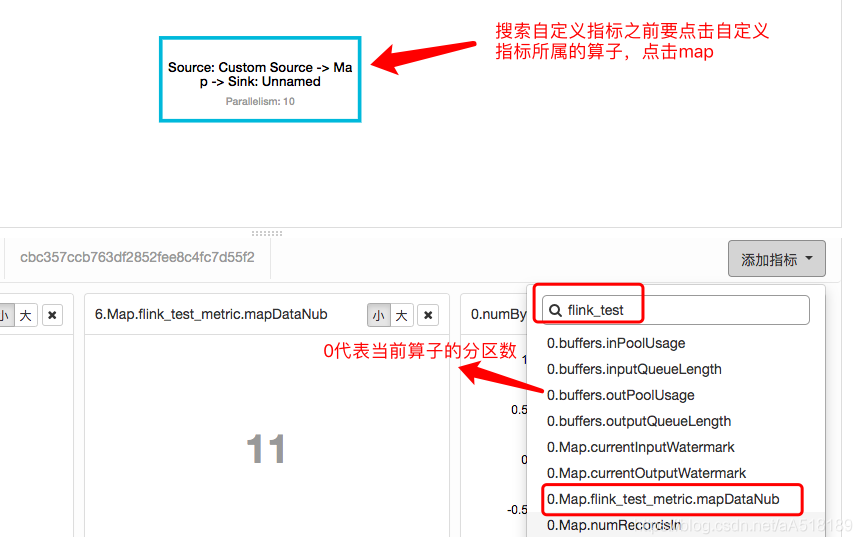
注意点:
- 搜索自定义或者查看某个指标需要点击DAG图中对应算子的名称
- 指标的前缀0,1,2….是指算子的分区数
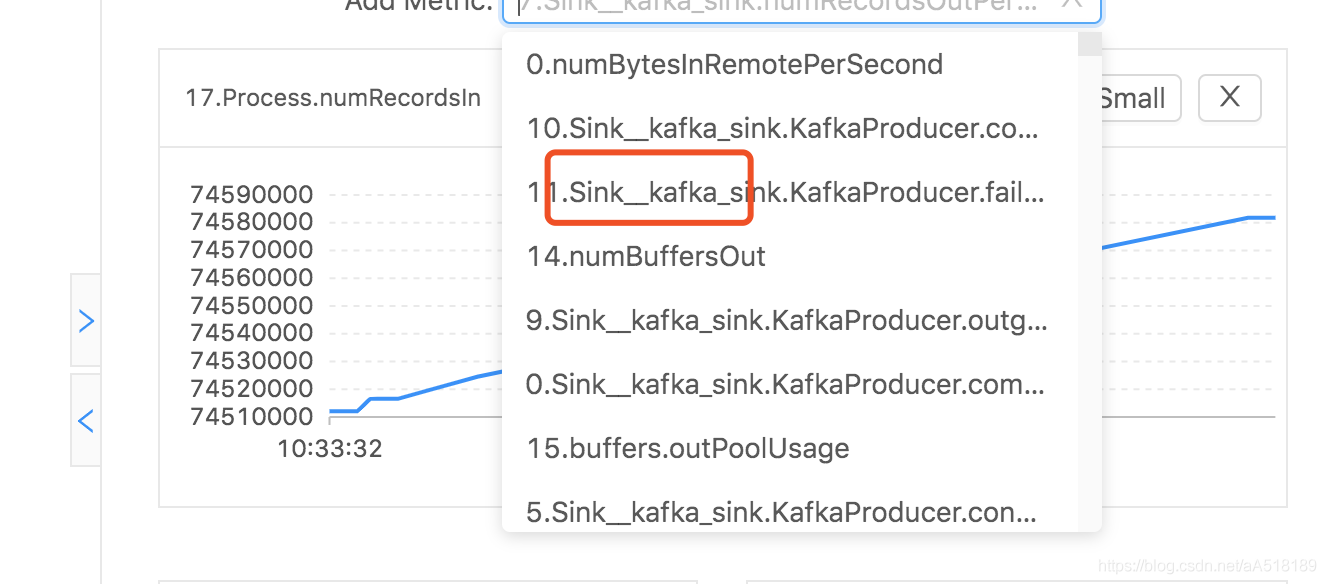
- 进行监控时,尽量不要对算子进行重命名,使用默认的名字,这样一套监控程序可以监控多个flink任务,比如对sink重新命名,如果不同的flink程序对sink的命名不一样,则一套监控无法监控多个flink程序
.addSink(KafkaSink.getProducer()).name("kafka_sink");
五、Flink UI 不显示算子数据接收和发送的条数
有时候我们Flink任务正常运行,数据也可以打印,而且都保存到数据库了,但是UI上面却不显示数据接收和发送的条数 ,导致无法进行指标监控和查查flink任务运行的具体情况,这是什么原因导致的呢?
原因:是因为默认情况下Flink开启了operator chain,所以当flink程序所有的算子都在一个chain里面时,也就是在一个DAG(task)里面,所有没有向下游发送数据,所以显示都为0。比如下图的情况所有指标都是0;

解决方案:第一种方法:在flink程序里添加自定义metric
第二种方法:使用startNewChain和disableChainin打断程序默认的operator chain
第三种方法:修改某个算子的并行度使其和上下游算子并行度不一致
六、Metric Reporter
Metrics可以暴露给外部系统,通过在flink配置文件conf/flink-conf.yaml配置即可,flink原生已经支持了很多reporter,如JMX、InfluxDB、Prometheus等等,同时也支持自定义reporter。Flink自带了很多Reporter,包括JMX、InfluxDB、Prometheus等等,接下来介绍下InfluxDB Reporter的使用。只需在flink配置文件conf/flink-conf.yaml中配置Influxdb相关信息即可,主要包括域名、端口号、用户密码等等。
flink1.10之后采用
metrics.reporter.influxdb.factory.class: org.apache.flink.metrics.influxdb.InfluxdbReporterFactory
metrics.reporter.influxdb.host: localhost
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flink
metrics.reporter.influxdb.consistency: ANY
metrics.reporter.influxdb.connectTimeout: 60000
metrics.reporter.influxdb.writeTimeout: 60000
metrics.reporter.influxdb.interval: 30 SECONDS
flink1.10之前
metrics.reporters: influxdb
metrics.reporter.influxdb.class: org.apache.flink.metrics.influxdb.InfluxdbReporter
metrics.reporter.influxdb.host: localhost
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flink_monitor
metrics.reporter.influxdb.username: flink-metrics
metrics.reporter.influxdb.password: 123
注意事项:收集flinkSQL任务的监控指标,如果用户书写的sql语句 insert into 或者insert overwrite 中单引号带有换行符,写入influxdb会报错
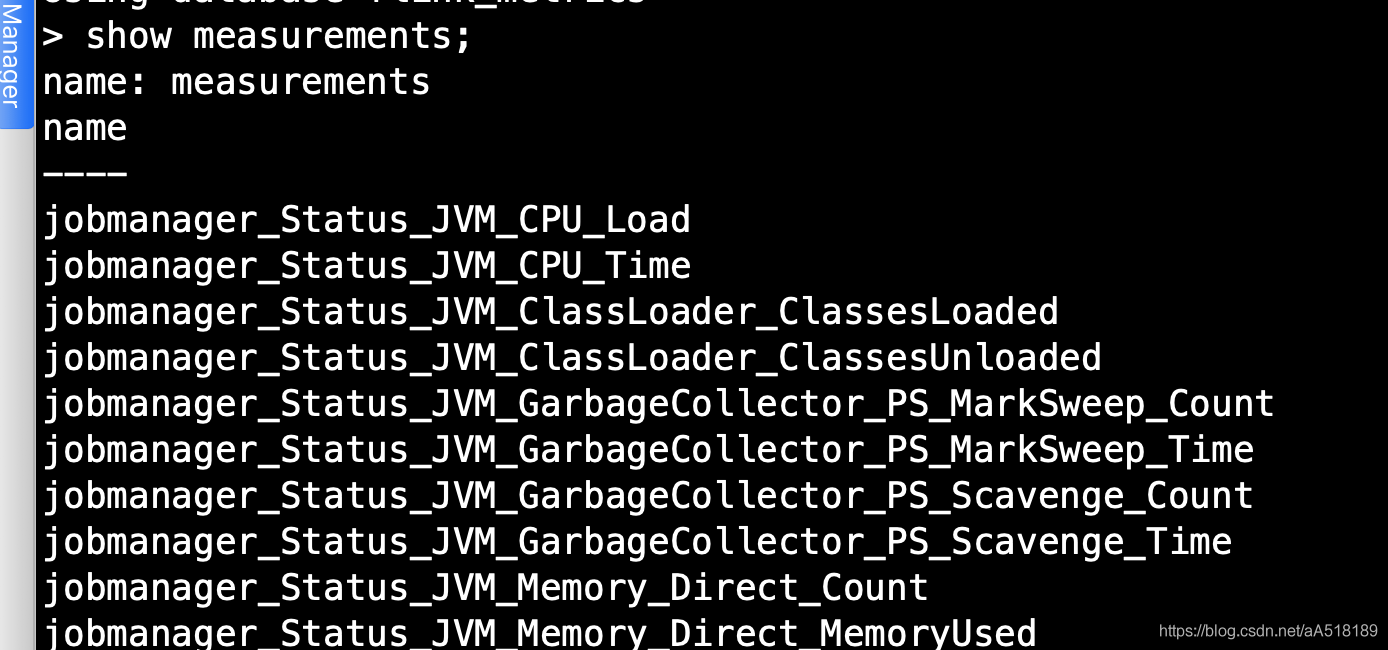
查看influxdb收集到监控信息,发现会自动给我生成数据库和measurement,所有的指标都存储在了具体的measurement中。
七、flink metric监控程序
前面介绍了flink公共的监控指标以及如何自定义监控指标,那么实际开发flink任务我们需要及时知道这些监控指标的数据,去获取程序的健康值以及状态。这时候就需要我们通过 flink REST API ,自己编写监控程序去获取这些指标。很简单,当我们知道每个指标请求的URL,我们便可以编写程序通过http请求获取指标的监控数据。
八、flink REST API监控程序
为了获取flink任务运行状态和吞吐量我们需要注意一下两点:
- flink集群模式需要知道 JobManager 的地址和端口(5004)
- 对于 flink on yarn 模式来说,则需要知道 RM 代理的 JobManager UI 地址,例如 http://yarn-resource-manager-ui/proxy/application_155316436xxxx_xxxx
1.获取flink任务运行状态(我们可以在浏览器进行测试,输入如下的连接)
http://yarn-resource-manager-ui/proxy/application_155316436xxxx_xxxx/jobs
返回的结果
{
jobs: [{
id: "ce793f18efab10127f0626a37ff4b4d4",
status: "RUNNING"
}
]
}
2.获取 job 详情
需要在/jobs/jobid
{
jid: "ce793f18efab10127f0626a37ff4b4d4",
name: "Test",
isStoppable: false,
state: "RUNNING",
start - time: 1551577191874,
end - time: -1,
duration: 295120489,
now: 1551872312363,
。。。。。。
此处省略n行
。。。。。。
}, {
id: "cbc357ccb763df2852fee8c4fc7d55f2",
parallelism: 12,
operator: "",
operator_strategy: "",
description: "Source: Custom Source -> Flat Map",
optimizer_properties: {}
}
]
}
}
九、更灵活的方式获取每个指标的请求连接
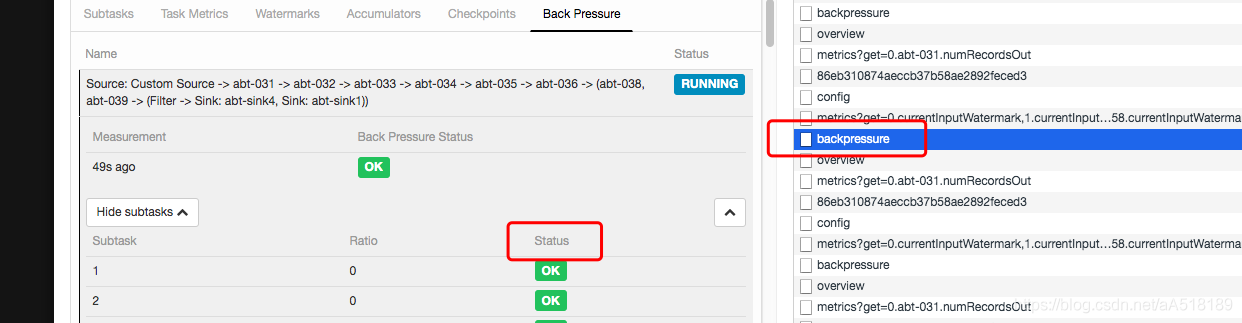
有人可能会问,这么多指标,难道我要把每个指标的请求的URL格式都记住吗?今天教大家一个小技巧,一个前端技术,就是进入flink任务的UI界面,按住F12进入开发者模式,然后我们点击任意一个metric指标,便能立即看到每个指标的请求的URL。比如获取flink任务的背压情况:
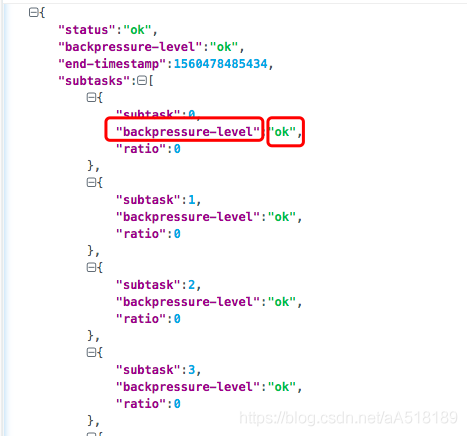
如下图我们点击某一个task的status,按一下f12,便看到了backpressue,点开backpressue就是获取任务背压情况的连接如下:
请求连接返回的json字符串如下:我们可以获取每一个分区的背压情况,如果不是OK状态便可以进行任务报警,其他的指标获取监控值都可以这样获取 简单而又便捷。
十、案例:实时获取yarn上flink任务运行状态
我们使用 flink REST API的方式,通过http请求实时获取flink任务状态,不是RUNNING状态则进行电话或邮件报警,达到实时监控的效果。
public class SendGet {
public static String sendGet(String url) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
public static void main(String[] args) {
String s = sendGet("http://127.0.0.1:5004/proxy/application_1231435364565_0350/jobs");
JSONObject jsonObject = JSON.parseObject(s);
String string = jsonObject.getString("jobs");
String substring = string.substring(1, string.length() - 1);
JSONObject jsonObject1 = JSONObject.parseObject(substring);
String status = jsonObject1.getString("status");
System.out.println(status);
}
}
结果

原创文章,作者:kk,如若转载,请注明出处:http://www.wangkai123.com/70/